Bayesian Audio Alignment Based on a Unified Generative Model of Music and Interpretation
This page presents some audio demonstrations of the inference results of our method.
We play back two interpretations, one on the right channel and one on the left.
The right channel audio is sliced and played back in such a way that
the onsets are aligned to the left channel.
The onsets are indicated by a short "ping" sound.
The onsets are extracted by finding where state of the common state sequence has changed.
In other words, we extract, as onsets, places where our model "thinks" the underlying
generative model has changed.
Example 1 - Chopin Mazurka Op.63
Interp. 1 - Interp. 2
Interp. 1 - Interp. 3
Interp. 1 - Interp. 4
Interp. 1 - Interp. 5
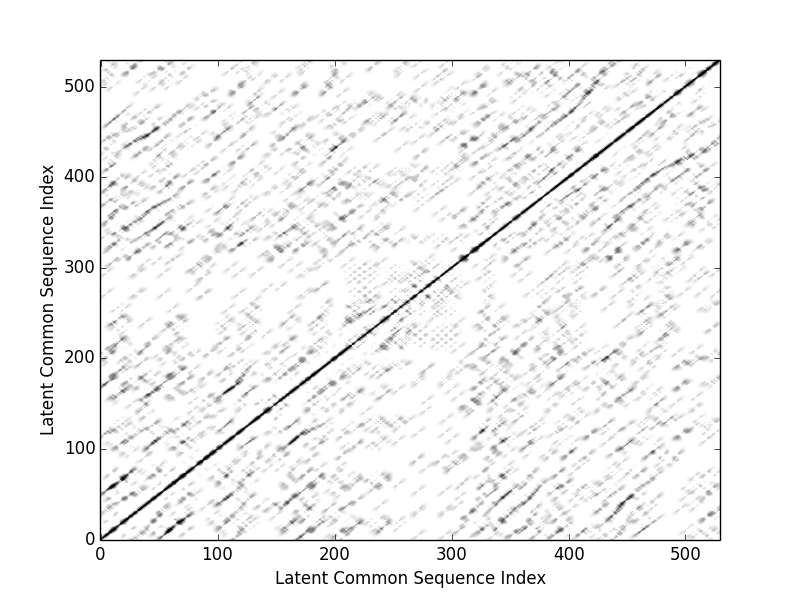
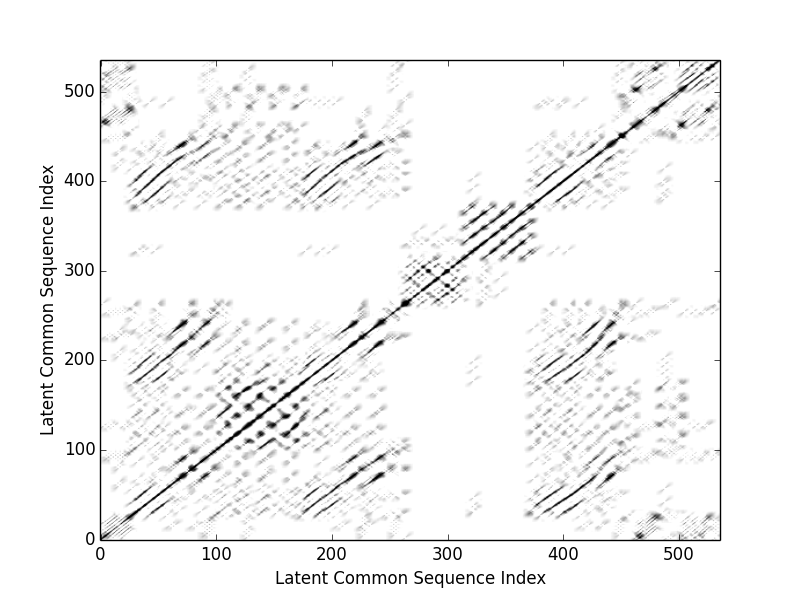
Similarity matrix of the entire piece
Example 2 - Chopin Mazurka Op.41
Interp. 1 - Interp. 2
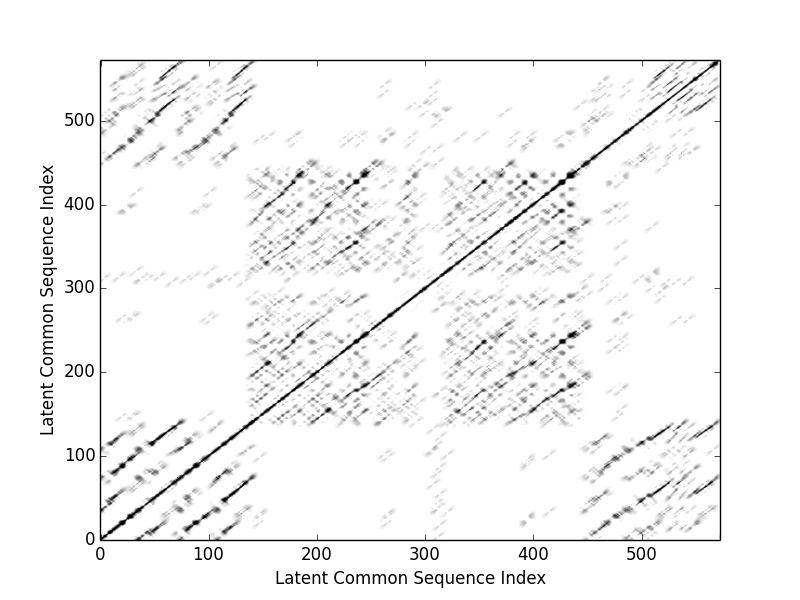
Similarity matrix of the entire piece
Example 3 - Chopin Mazurka Op.67
Interp. 1 - Interp. 2
Interp. 1 - Interp. 3
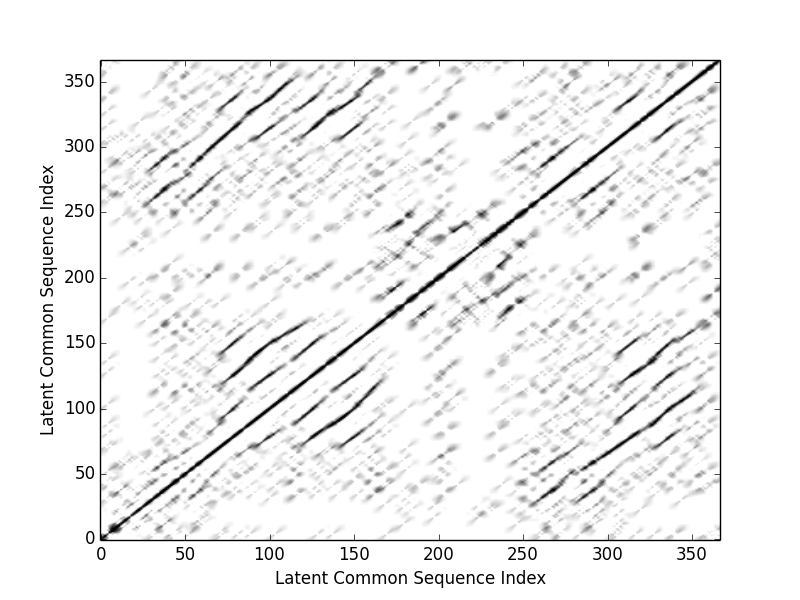
Similarity matrix of the entire piece
Some examples of errors
The most common mode of failure is when the alignment gets "lost" for a while.
When this happens, one sequence tends to stay in some segment for too long and fast-forward
to compensate for it. Such an error, however, is less likely to happen than when using
LRHMM-based model, because structural information can be used as a cue for the model to reorient itself.