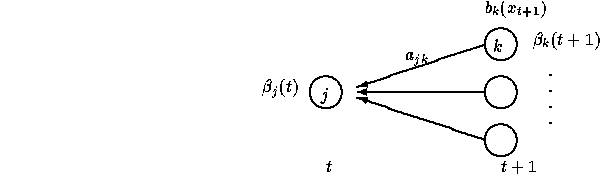
This algorithm is to find the one state sequence that was most likely to have generated the observation sequence. It is very similar to the Forward Algorithm, the main difference being that instead of evaluating a summation at each cell, we evaluate the maximum:
This implicitly identifies the single best predecessor state for each
cell in the trellis. If we explicitly identify that best predecessor
state, saving a single backpointer in each cell in the trellis, then
by the time we have evaluated ![]() at the final state at the final
time frame, we can retrace those backpointers from the final cell to
reconstruct the whole state sequence. Figure 2.9 illustrate
the Viterbi path. Once we have the state sequence, we can segment the
speech by the alignment path.
at the final state at the final
time frame, we can retrace those backpointers from the final cell to
reconstruct the whole state sequence. Figure 2.9 illustrate
the Viterbi path. Once we have the state sequence, we can segment the
speech by the alignment path.