![]()
The pronunciation scoring algorithms are based on phonemic time alignments generated by the speech recognition system. In this application, the transcription of the utterance is known because the learner is prompted to utter a word or sentence from the system. By using the alignments and the native-trained HMMs, the system computes various scores that rely on the phoneme-level statistics. Our pronunciation scoring method uses the HMMs trained using the database of native speakers to generate phonetic time alignments of the learner's speech. It is a good measure of the similarity between model speech and learners' speech. From the above segmentations, we use the following probability measures to obtain scores for each phoneme segment. For each segment, the HMM log-likelihood score S is calculated as
![]()
where 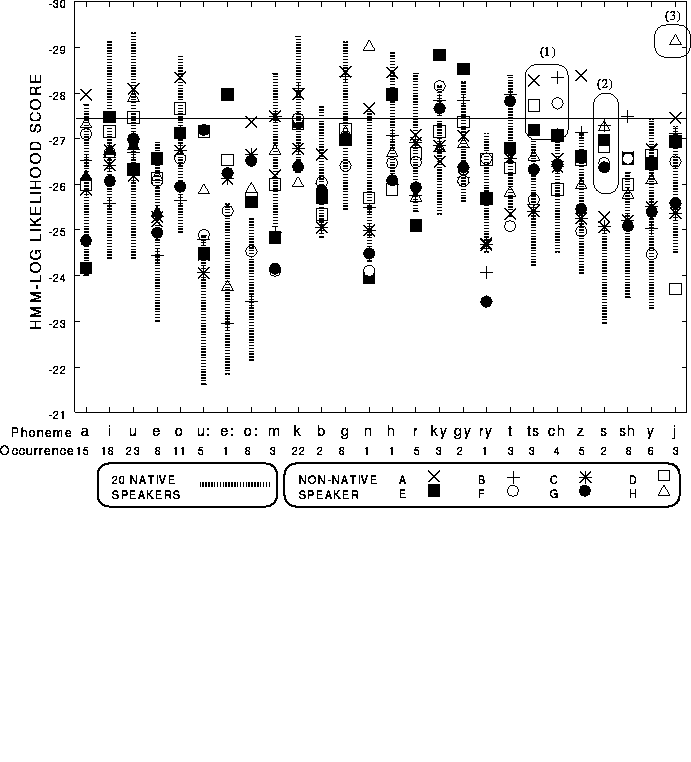 is the likelihood of the current frame with
observation vector
is the likelihood of the current frame with
observation vector ![]() , d is the duration (in frames) of the
phoneme segment, and
, d is the duration (in frames) of the
phoneme segment, and 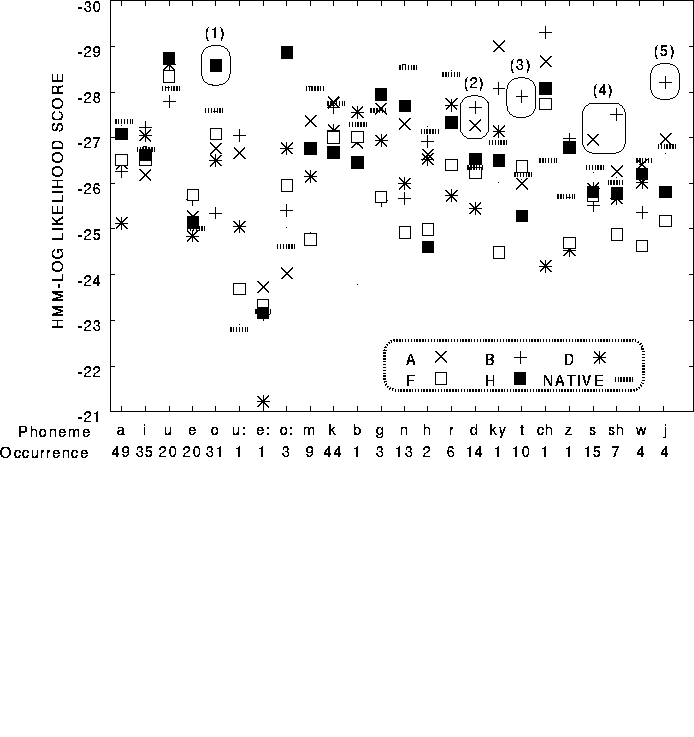 is the starting frame index of the phoneme
segment. Dividing by d allows us to eliminate the dependency of the
pronunciation score on the duration of the phoneme, since the HMM
log-likelihood score has the property to depend on the length of
observation vectors, i.e., the longer it is, the lower the score
is. An example of these scores is shown on the bottom window in
Figure 3.3. The /silB/, /silE/ symbols are used to make
the model more robust by absorbing the noises in the beginning and end
part of utterance. In this case, it is realized that the learner's
/sh/ score is relatively lower than the model's score.
is the starting frame index of the phoneme
segment. Dividing by d allows us to eliminate the dependency of the
pronunciation score on the duration of the phoneme, since the HMM
log-likelihood score has the property to depend on the length of
observation vectors, i.e., the longer it is, the lower the score
is. An example of these scores is shown on the bottom window in
Figure 3.3. The /silB/, /silE/ symbols are used to make
the model more robust by absorbing the noises in the beginning and end
part of utterance. In this case, it is realized that the learner's
/sh/ score is relatively lower than the model's score.