ICTイノベーション2008 リーフレット
- 概要
-
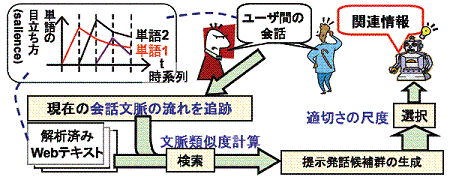
本研究では、複数ユーザ間の会話支援システムの実現を目指し、会話に参加して文脈的に近い情報を提示するというタスクを扱っています。そのためには、人間同士の会話文脈を追跡することが必要不可欠です。つまり、ユーザ達がその瞬間に何に着目しているかを追跡できて初めて、似た対象に着目した情報の提示が可能となります。そのために本研究では、先行文脈に含まれる単語群の目立ち方 (salience) の尺度を設計し、その統計的な計測手法を開発しました。これにより、従来困難であった「文脈の流れ」の類似度計算が可能になると考えています。
- 産業への発展例
-
本研究が発展すると、これまでのようにユーザがPCに向かって検索語を入力するのではなく、ユーザ同士の会話文脈から検索語を自動生成し、適切な検索結果を提示するクエリーフリー検索が可能になります。これにより、以下のようなサービスの実現が期待されます。
- 会話支援: 会話の流れに関連する話題提示サービス
- 会話連動型広告: 会話の流れに連動して切り替わる広告
- 会議支援: 会議の流れに関連する過去の議事録を提示
- 文章執筆支援: 文章の流れに関連する情報を提示
- 詳細
-
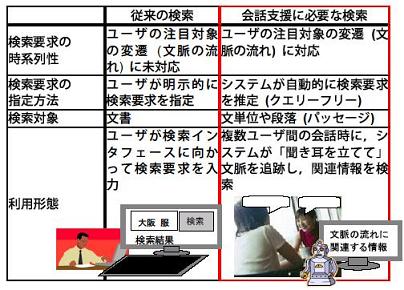
会話支援のためには、従来の検索とは異なる要求を満たす検索が必要となります。 次の表は、会話支援に必要な検索の要求項目を表したものです。
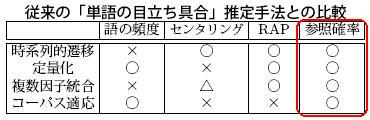
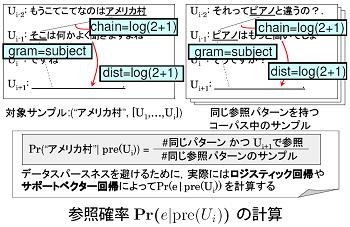
参照確率は、「目立っている単語ほど継続的に参照されやすい」という性質を利用した尺度です。 われわれは、この尺度が従来の言語学的知見との整合性を備えていることを、実際の大規模言語データ(日本語と英語) の上で確かめました。
- 現状と計画
- 現在、書きおこし会話データに対する文脈追跡システムは開発済みです。今後2年間(2007年4月から2009年3月)、日本学術振興会の支援を受けてプロジェクトを推進し、2年後には実証実験を行う計画になっています。
- 研究者
-
白松 俊,
駒谷 和範,
奥乃 博
(京都大学 情報学研究科 知能情報学専攻 奥乃研究室)