Y. Bando, K. Itoyama, M. Konyo, S. Tadokoro, K. Nakadai, K. Yoshii, T. Kawahara, and H. G. Okuno
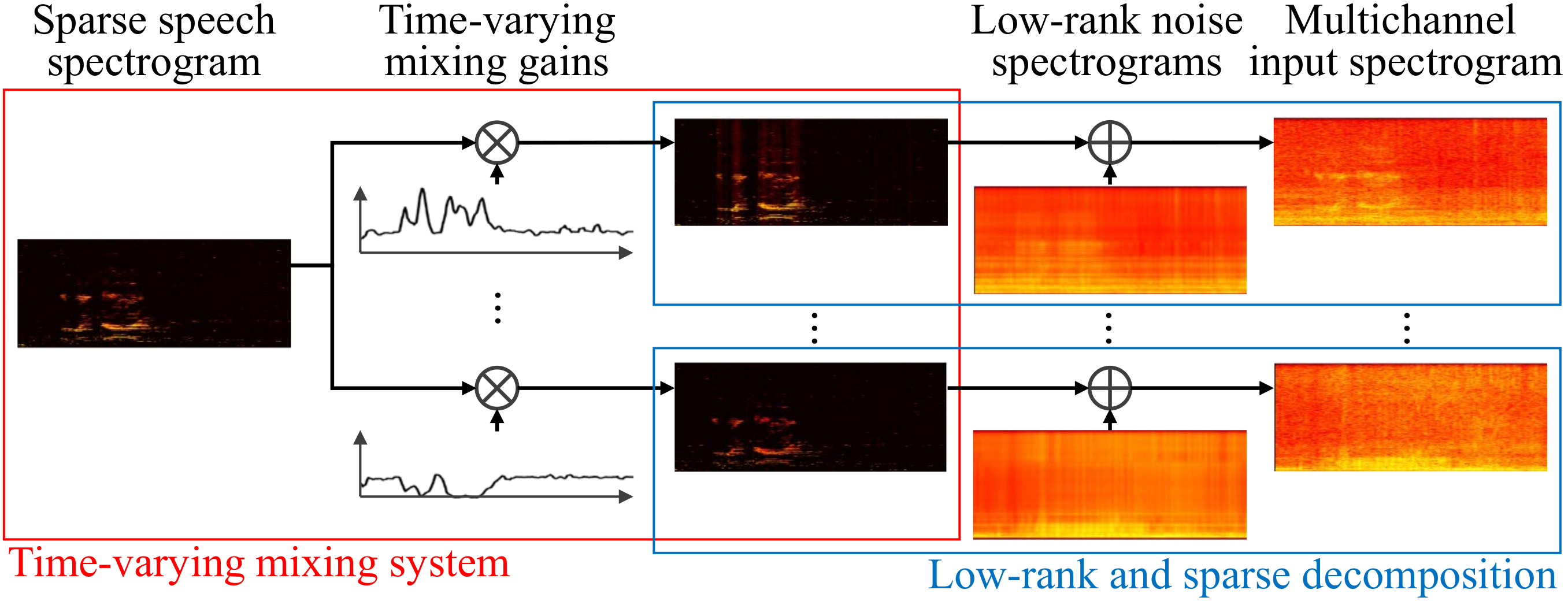
Abstract: This paper presents a blind multichannel speech enhancement method that can deal with the time-varying layout of microphones and sound sources. Since nonnegative tensor factorization (NTF) separates a multichannel magnitude (or power) spectrogram into source spectrograms without phase information, it is robust against the time-varying mixing system. This method, however, requires some prior information such as the spectral bases (templates) of each source spectrogram in advance. To solve this problem, we develop a Bayesian model called robust NTF (Bayesian RNTF) that decomposes a multichannel magnitude spectrogram into target speech and noise spectrograms based on their sparseness and low-rankness. The method is applied to the challenging task of speech enhancement for a microphone array distributed on a hose-shaped rescue robot. When the robot searches for victims under collapsed buildings, the layout of the microphones changes over time and some of them often fail to capture target speech. The proposed method robustly works under such situation because of its formulation of time-varying mixing system. Experiments using a 3-m hose-shaped robot with eight microphones show that our method outperforms conventional blind methods by the signal-to-noise ratio of 1.27dB.

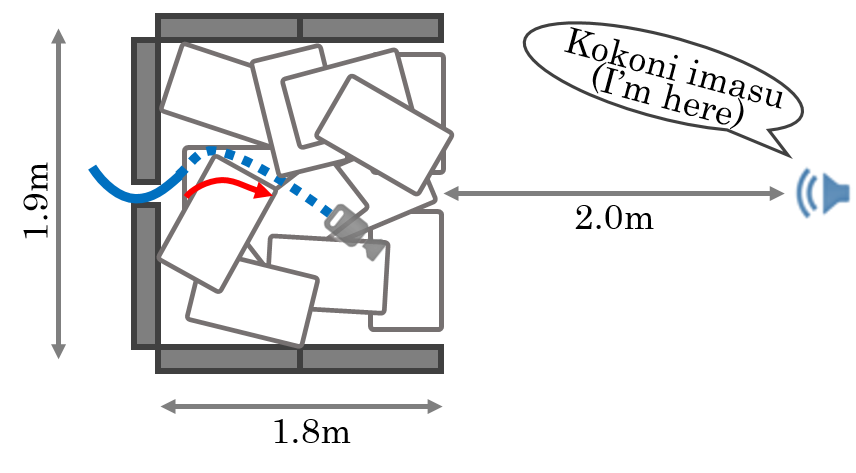
Experimental Conditions
To simulate rubble disturbing sound propagation, styrene foam boxes and wooden plates were piled up. A loudspeaker for playing back target speech signals was put 2 m away from this rubble. The target signals were the four male and female speech recordings calling for rescue in Japanese (e.g., "Ôi" and "Kokoniimasu") and the loudspeaker was calibrated so that its sound pressure level for each utterance was 80 dB. The robot was inserted from behind the rubble and captured eight-channel audio signals (mixtures of ego-noise and each target speech) for 10 seconds during the insertion.

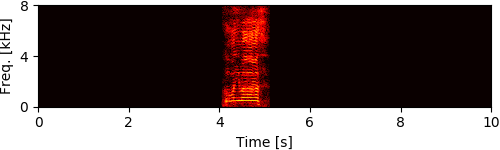
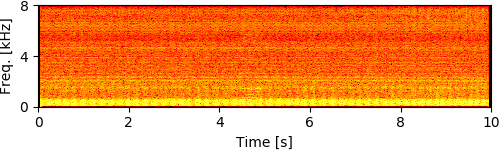
Experimental Results
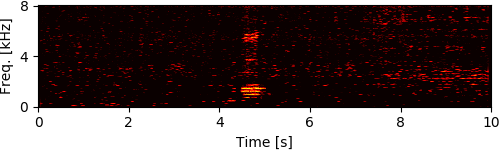
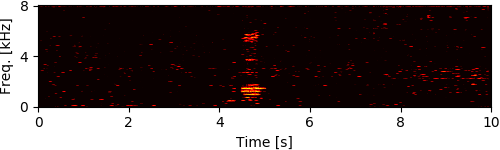
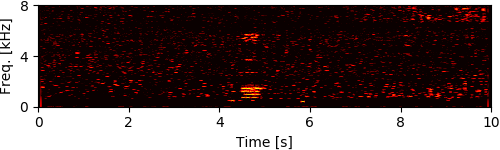
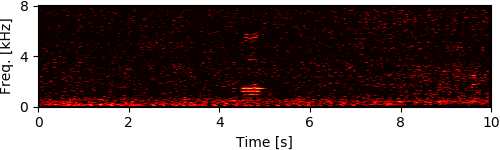
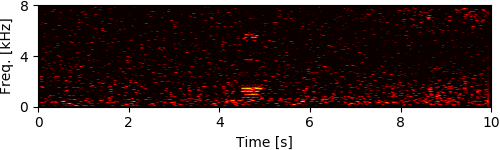
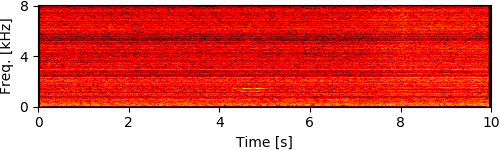
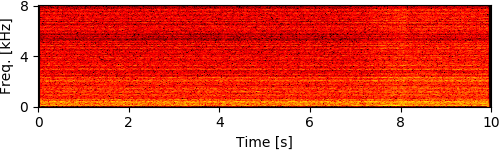
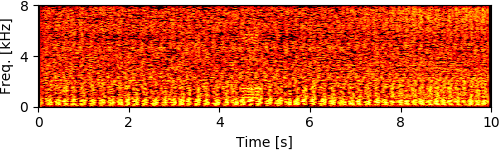
[1] Y. Bando+, "Human-voice enhancementbased on online RPCA for a hose-shaped rescue robot with a microphone array," in IEEE
SSRR, 2015, pp. 1-6.
[2] C. sun+, "Noise reduction based on robust principal component analysis," JCIS, vol. 10, no. 10, pp. 4403-4410,
2014.
[3] D. Kitamura+, "Efficient multichannel nonnegative matrix factorization exploiting rank-1 spatial model," in IEEE
ICASSP, 2015, pp. 276-280.
[4] N. Ono+, "Stable and fast update rules for independent vector analysis based on auxiliary function technique,"
in IEEE WASPAA, 2011, pp. 189-192.
[5] H. Nakajima+, “An easily-configurable robot audition system using histogram-based recursive level estimation,”
in IEEE/RSJ IROS, 2010, pp. 958–963.