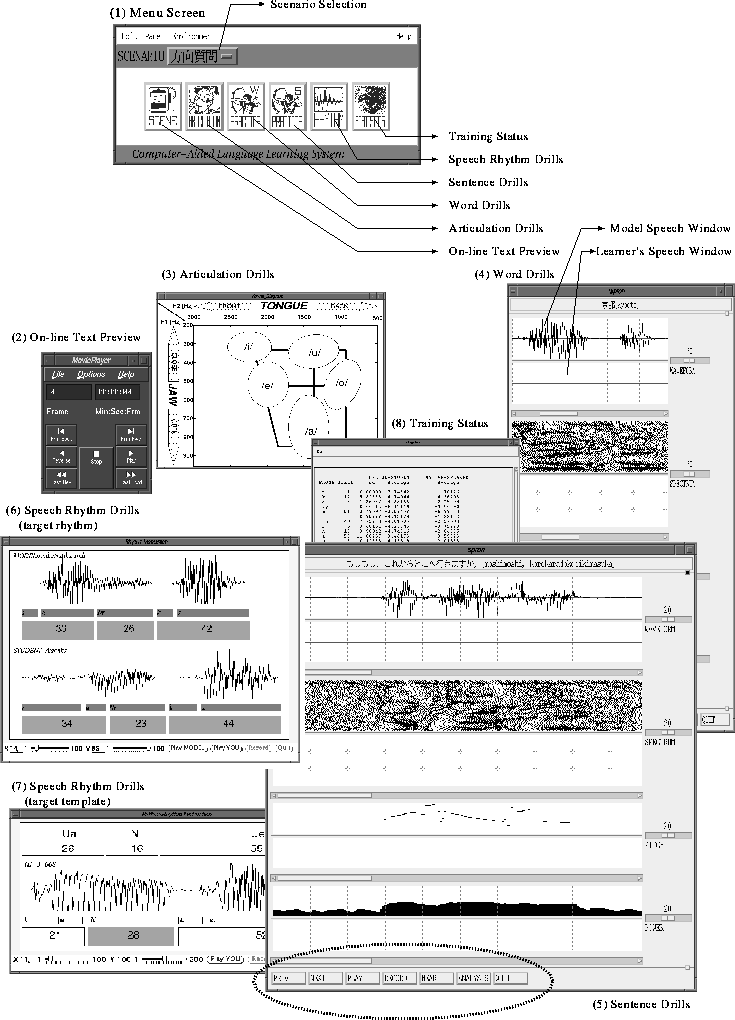
Statistical decision theory can be used as a means to establish the discriminant functions for probabilistic patterns governed by known probability functions. By Bayes' rule we can write
where p(X|i) is the probability that X occurs, given that it is a pattern belonging to category i; regarded as a function of i, p(X|i) is often called the likelihood of i with respect to X; p(i) is the a priori probability of occurrence of category i; and p(X) is the probability that X occurs regardless of its category.
The probability p(X) is calculated as follows:
![]()
The various terms used in Eq.(2.12) are defined below.
![]()
is a ![]() column vector representing the pattern.
column vector representing the pattern.
![]()
is a ![]() column vector. It has the property of being equal
to the expected value of X, i.e., M=E[X], and is therefore
called the mean vector.
column vector. It has the property of being equal
to the expected value of X, i.e., M=E[X], and is therefore
called the mean vector.
![]()
is a symmetric, positive definite matrix, called the covariance
matrix.
The i, j component ![]() of the covariance matrix
of the covariance matrix ![]() is given by
is given by
![]()
for all i, j = 1, ![]() , d; in particular,
, d; in particular, ![]() is
the variance of
is
the variance of ![]() .
We can also write
.
We can also write ![]() in the compact form
in the compact form
![]()
The inverse of ![]() is
is ![]() , and the determinant of
, and the determinant of
![]() is
is 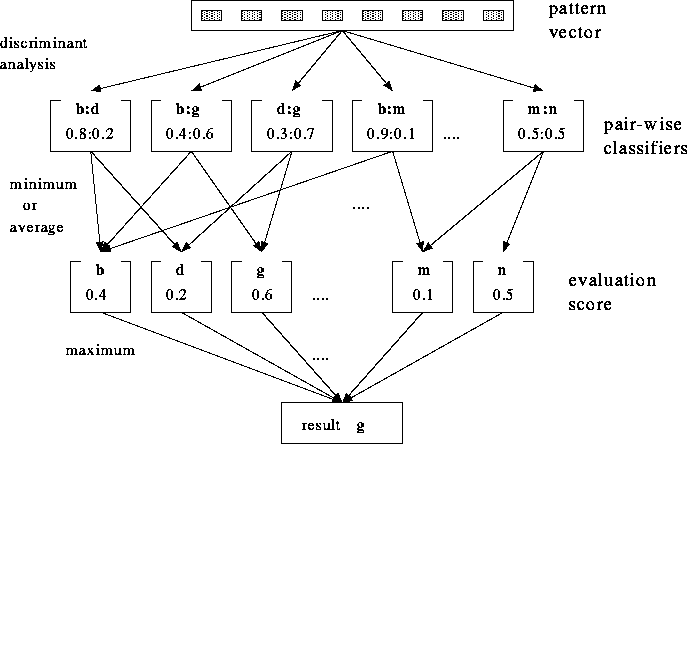 . Since the d-variate normal probability
distribution is completely specified by the mean vector M and
covariance matrix
. Since the d-variate normal probability
distribution is completely specified by the mean vector M and
covariance matrix ![]() .
.
The probability p(X|i) is also calculated as below if we define R
mean vectors 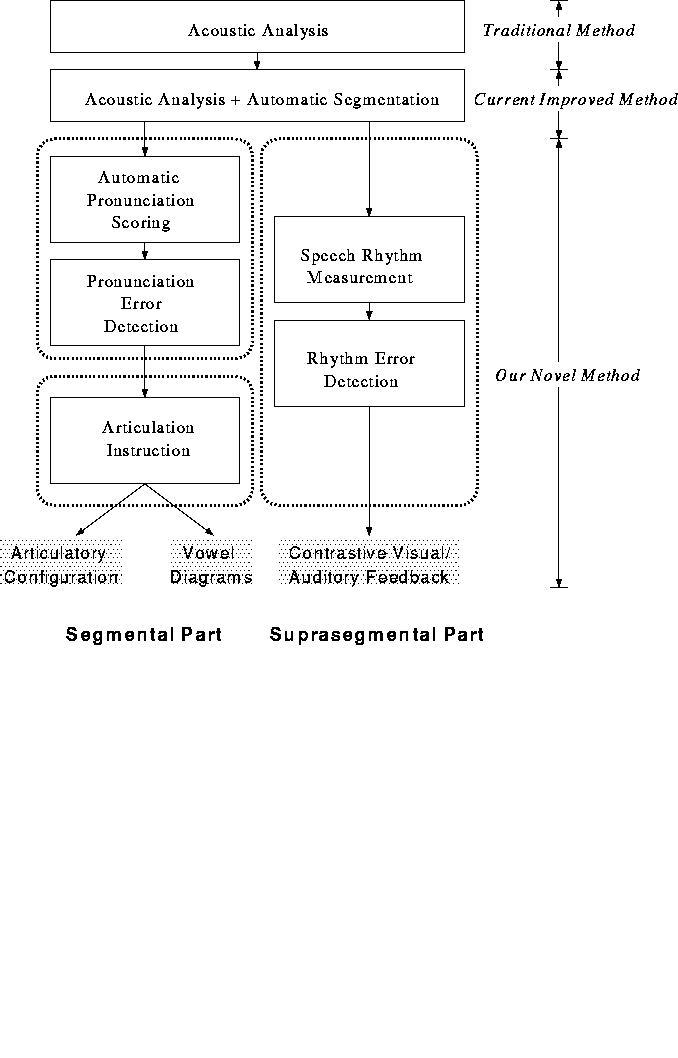 and R covariance matrices
and R covariance matrices ![]() for i = 1,
for i = 1,
![]() , R
, R